# Associate Rule Mining 关联规则挖掘
# Market Basket Analysis 购物车分析
Associate Rule Mining 最早被应用于 Market Basket Analysis
Goal of MBA is to find associations (affinities) among groups of items occurring in a transactional database
MBA 的目标是在交易数据库中出现的一组项目之间找到联系 (亲缘关系)- has roots in analysis of point of sale data, as in supermarkets
根源在于销售点数据的分析,比如在超市 - but, has found applications in many other areas
但是,已经应用在许多其他领域
- has roots in analysis of point of sale data, as in supermarkets
Association Rule Discovery 关联规则发现
- most common type of MBA technique
最常见的 mba 技术 - Find all rules that associate the presence of one set of items with that of another set of items.
找到所有将一组项目的存在与另一组项目的存在联系起来的规则。 - Example: 98% of people who purchase tires and auto accessories also get automotive services done
例子:98% 的人购买轮胎和汽车 - We are interested in rules that are
我们对以下规则感兴趣。- non trivial (and possibly unexpected)
非同小可 (可能出乎意料)。 - actionable
可操作的。 - easily explainable
易于解释
- non trivial (and possibly unexpected)
- most common type of MBA technique
# What Is Association Mining? 什么是关联挖掘?
- Association rule mining searches for relationships between items in a data set:
关联规则挖掘搜索数据集中项目之间的关系:- Finding association, correlation, or causal structures among sets of items or objects in transaction databases, relational databases, etc.
在事务数据库、关系数据库等中查找项目或对象集合之间的关联、相关性或因果结构。
- Finding association, correlation, or causal structures among sets of items or objects in transaction databases, relational databases, etc.
不是通过给定某个值来衡量关联,而是制定一条规则,来告诉你原因是什么,结果是什么
所有的规则都要有左右两边,左边是原因,右边是结果,规则后面还要加上两个数字来描述它,分别是 support 和 confidence。
Rule form:
规则表单:Body → Head[support, confidence]BodyandHeadcan be represented as sets of items or as predicatesBody和Head可以表示为项集或谓词。
Examples:
{diaper, milk, Thursday} → {beer} [0.5%, 78%]buys(x, "bread") → buys(x, "milk") [0.6%, 65%]major(x, "CS") /\takes(x, "DB") → grade(x, "A") [1%, 75%]age(X,30-45) /\income(X, 50K-75K) → buys(X, SUVcar)age="30-45", income="50K-75K" → car="SUV"
It can be considered as an unsupervised learning process.
可以认为是一个非监督式学习过程
Because we have no idea about what kind of patterns we can find
因为不知道能找到什么样的模式
# Different Kinds of Association Rules 不同类型的关联规则
- Boolean vs. Quantitative 布尔 vs. 定量
- associations on discrete and categorical data vs. continuous data
离散和分类数据 vs. 连续数据的关联 - Single vs. Multiple Dimensions 单维 vs. 多维空间
- one predicate = single dimension; multiple predicates = multiple dimensions
单谓词 = 单维;多谓词 = 多维 buys(x, "milk") → buys(x, "butter")age(X,30 45) / income(X, 50K 75K) → buys(X, SUVcar)
- one predicate = single dimension; multiple predicates = multiple dimensions
- Single level vs. multiple level analysis 单层次分析 vs. 多层次分析
- Based on the level of abstractions involved
基于涉及的抽象级别 buys(x, "bread") → buys(x, "milk")buys(x, "wheat bread") → buys(x, 2% milk)
- Based on the level of abstractions involved
- Simple vs. constraint based 简单 vs. 基于约束
- Constraints can be added on the rules to be discovered
可以在要发现的规则上添加约束
# Basic Concepts
We start with a set of items and a set of transactions
我们从一组 项目和一组 交易开始- is all of the transactions relevant to the mining task
是与挖掘任务相关的所有事务
A transaction is a set of items (a subset of ):
交易 是一组项目 ( 的子集)An Association Rule is an implication on itemsets and , denoted by
X → Y, where
关联规则意味着对 和 关系的暗示,用X → Y表示,其中The rule meets a minimum confidence of , meaning that of transactions in which contain also contain
该规则满足 的最小置信度,这意味着 中有 的包含 的交易也包含了In addition a minimum support of is satisfied
此外,最小支持度 满足
# Support and Confidence 支持度和置信度
- Find all the rules
X→Ywith minimum confidence and support
以最小置信度和支持度,找到所有X→Y的规则
- Support 支持度
- = probability that a transaction contains
= 交易包含 的概率
i.e., ratio of transactions in which , occur together to all transactions
例如, 和 一起出现的交易占所有交易的比率 - Confidence 置信度
- = conditional probability that a transaction having also contains
= 具有 的交易也包含 的条件概率
i.e., ratio of transactions in which , occur together to those in which occurs.
即 和 一起出现的交易占出现 的交易的比率。
- In general confidence of a rule
LHS → RHScan be computed as the support of the whole itemset divided by the support ofLHS:
一般来说,规则LHS→RHS的置信度可以计算为整个项集的支持度除以LHS的支持度:
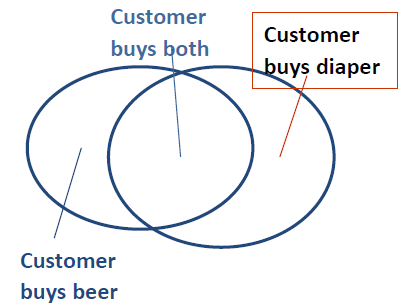
# Example
| Transaction ID | Items Bought |
|---|---|
| 1001 | A, B, C |
| 1002 | A, C |
| 1003 | A, D |
| 1004 | B, E, F |
| 1005 | A, D, F |
Itemset {A, C} has a support of 2/5 = 40%
同时有 A 和 C 的只有 1001 和 1002 两个,总共有 5 个交易
Rule {A} → {C} has confidence of 50%
{A} → {C}置信度是指给定 A 的 C 的概率
先找到有 A 的交易包括了,1001、1002、1003、1005 四个
在这些交易中,包含了 C 的交易有 1001 和 1002 两个
Rule {C} → {A} has confidence of 100%
反过来,
{C} → {A}置信度是指给定 C 的 A 的概率
先找到有 C 的交易包括了,1001、1002 四个
在这些交易中全部包含了 A
Support for {A, C, E} ?
同时有 A、C 和 E 的交易没有,所以 support = 0
Support for{A, D, F}?
同时有 A、D 和 F 的交易有 1005 一个,所以 support = 1/5 = 20%
Confidence for {A, D} → {F} ?
{A, D} → {F}置信度是指给定 A 和 D 的 F 的概率
先找到同时包含 A 和 D 的交易包括了,1003、1005 两个
在这些交易中,包含了 F 的交易有 1005 一个,故置信度为 50%
Confidence for {A} → {D, F} ?
{A} → {D, F}置信度是指给定 A 的 同时包含 D 和 F 的交易的概率
先找到有 A 的交易包括了,1001、1002、1003、1005 四个
在这些交易中,同时包含了 D 和 F 的交易有 1005 一个,故置信度为 1/4 = 25%
# Improvement (Lift) 优化值
- High confidence rules are not necessarily useful
高置信度规则不一定有用不能只看置信度而忽视支持度,两者都很重要
- what if confidence of
{A, B} → {C}is less than ?
如果{A, B} → {C}的置信度小于,该怎么办? - improvement gives the predictive power of a rule compared to just random chance:
与随机概率相比,优化值可以提供规则的预测能力:Lift value = 规则的置信度除以结果的支持度
- what if confidence of
Itemset {A} has a support of 4/5
Rule {C} → {A} has confidence of 2/2
通过置信度除以支持度来计算优化值。
Improvement =5/4=1.25
Itemset {A} has a support of 4/5
Rule {B} → {A} has confidence of 1/2
通过置信度除以支持度来计算优化值。
Improvement =5/8=0.625
# Steps in Association Rule Discovery 关联规则发现的步骤
# Find the frequent itemsets 查找常用项集
- Frequent item sets 频繁项集
- are the sets of items that have minimum support
是指支持度最低的项集 - a subset of a frequent itemset must also be a frequent itemset
频繁项集的子集也必须是频繁项集- if
{A, B}is a frequent itemset , both{A}and{B}are frequent itemsets
如果{A, B}是频繁项集,{A}和{B}都是频繁项集 - this also means that if an itemset that doesn't satisfy minimum support, none of its supersets will either (this is essential for pruning search space)
这也意味着,如果一个项集不满足最小支持度,那么它的任何超集都不会满足(这对于修剪搜索空间至关重要)
- if
- are the sets of items that have minimum support
# Apriori Algorithm: Find Frequent Itemset Apriori 算法:寻找频繁项集
: Candidate itemset of size
大小为 的候选项集: Frequent itemset of size
大小为 的频繁项集
= { frequent items };
for( = 1; ; ++) do begin // 从 = 1 开始循环检查
= candidates generated from ;
for each transaction in database do
increment the count of all candidates in that are contained in
增加 中包含在 中的所有候选项的计数
= candidates in with min_support
end
return ;
- Join Step: 连接步骤
- is generated by joining with itself
是通过将 与其自身连接而生成的 - Prune Step: 修剪步骤
- Any -itemset that is not frequent cannot be a subset of a frequent -itemset
任何不常见的 项集都不能成为常见的 项集的子集
# Example of Generating Candidates
=
{abc, abd, acd, ace, bcd}Self joining: .
abcdfromabcandabdacdefromacdandace
Pruning:
acdeis removed becauseadeis not in .
=
{abcd}
# Apriori Algorithm - An Example
Assume minimum support = 2
假定最小支持度为 2
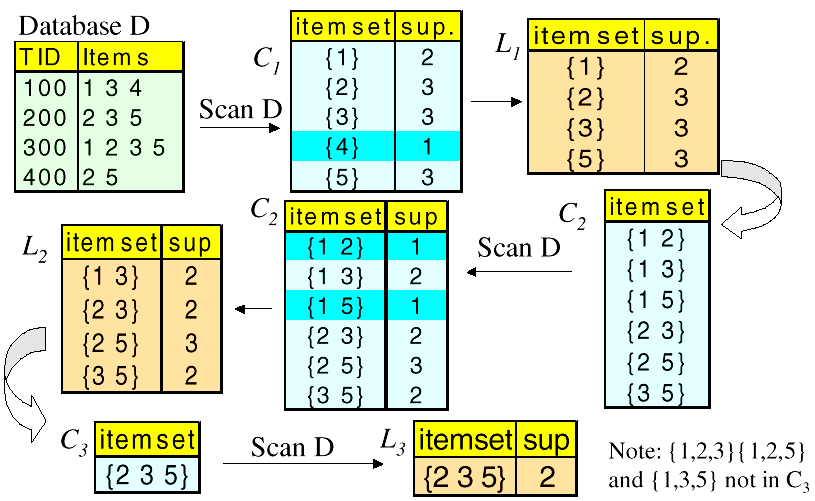
Database D 中一共有 5 种 items {1,2,3,4,5},即
第一步计算 每个值的支持度,比如值 1,在 database D 中出现了 2 次,值 2 则出现 3 次,以此类推。
按照最小支持度为 2 的假定,支持度低于 2 的需要移除,因此得到 = {1,2,3,5},移除了 {4},因此 就是大小为 1 的频繁项集。
第二步,将 中的项进行混合,成为大小为 2 的新集合,即。
继续计算 每个值的支持度,并移除支持度低于 2 的,得到,因此 就是大小为 2 的频繁项集。
第三步,混合 中的项,试着找到大小为 3 的项集,即。
在 中,{1,2} 已经不是频繁项集了,所以 中也就不应存在 {1,2,3};同理,{1,5} 也不是频繁项集,因此 {1,2,5} 和 {1,3,5} 也不是。
计算支持度,得到 。
接下来是 = 4,在这种情况下,需要混合 中的项目,以获得大小为 4 的项集,但已经没有如此多的项,故运算结束。
如果一个项集不满足最小支持度,那么它的任何超集都不会满足
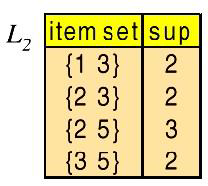

The final “frequent” item sets are those remaining in and .
最后的 “频繁” 项集是那些剩余的 和 。
However, {2,3} , {2,5} , and {3,5} are all contained in the larger item set {2, 3, 5} .
然而, {2,3} , {2,5} 和 {3,5} 都包含在较大的项集 {2, 3, 5} 中。
Thus, the final group of item sets reported by Apriori are {1,3} and {2,3,5} .
因此,Apriori 报告的最后一组项集是 {1,3} 和 {2,3,5} 。
These are the only item sets from which we will generate association rules.
这是唯一的项集,我们将从中生成关联规则。
# Use the frequent itemsets to generate association rules 使用频繁项集生成关联规则
- Only strong association rules are generated
只产生强关联规则 - Frequent itemsets satisfy minimum support threshold
频繁项集满足最小支持度 - Strong rules are those that satisfy minimum confidence threshold
强规则满足最小置信度
For each frequent itemset, , generate all non-empty subsets of
For every non-empty subset of do
if support()/support() ≥ min_confidence then
output rule s → (f-s)
end
# Example Continued
Item sets:
{1,3}and{2,3,5}Recall that confidence of a rule
LHS → RHSis Support of itemset (i.e. ) divided by support ofLHS.
Candidate rules for {1,3} | Candidate rules for {2,3,5} | ||||
|---|---|---|---|---|---|
| Rule | Conf. | Rule | Conf. | Rule | Conf. |
{1}→{3} | 2/2 = 1.0 | {2,3}→{5} | 2/2 = 1.00 | {2}→{5} | 3/3 = 1.00 |
{3}→{1} | 2/3 = 0.67 | {2,5}→{3} | 2/3 = 0.67 | {2}→{3} | 2/3 = 0.67 |
{3,5}→{2} | 2/2 = 1.00 | {3}→{2} | 2/3 = 0.67 | ||
{2}→{3,5} | 2/3 = 0.67 | {3}→{5} | 2/3 = 0.67 | ||
{3}→{2,5} | 2/3 = 0.67 | {5}→{2} | 3/3 = 1.00 | ||
{5}→{2,3} | 2/3 = 0.67 | {5}→{3} | 2/3 = 0.67 | ||
Assuming a min. confidence of 75%, the final set of rules reported by Apriori are: {1}→{3} , {3,5}→2 , {5}→{2} and {2}→{5} .
假设最小置信度为 75%,则报告的最终规则集为 {1}→{3} , {3,5}→2 , {5}→{2} and {2}→{5} 。
建议先减少支持度,不要一开始就降低置信度
# Extension 扩展
# Multiple-Level Rules 多级规则
- Items often form a hierarchy
物品往往形成等级制度- Items at the lower level are expected to have lower support
较低级别的项目预计支持度较低 - Rules regarding itemsets at appropriate levels could be quite useful
关于适当级别项集的规则可能相当有用 - Transaction database can be encoded based on dimensions and levels
事务数据库可以根据维度和级别进行编码
- Items at the lower level are expected to have lower support
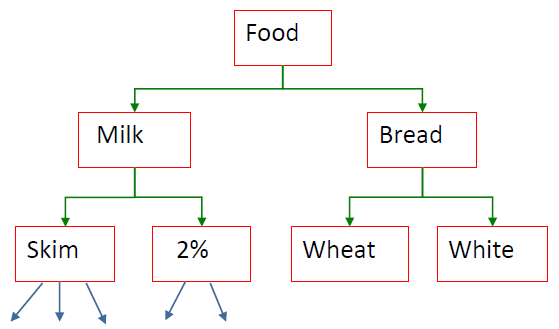
- Pros: find finer-grained rules
优点:找到更细粒度的规则 - Cons: support may be low
缺点:支持率可能很低
为了能更好的计算,可以适当降低支持度的要求,比如从 50% 降到 30%
# Quantitative Rules 定量规则
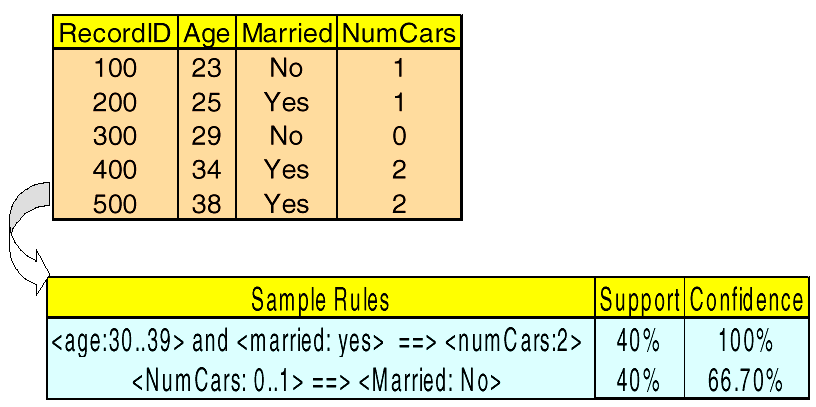
- Handling quantitative rules may require mapping of the continuous
处理定量规则可能需要映射的连续 - variables into Boolean or categorical ones
变量转换成布尔值或范畴值
# Web Mining 网络挖掘
# What is Web Mining
From its very beginning, the potential of extracting valuable knowledge from the Web has been quite evident
从一开始,从网络中提取有价值知识的潜力就相当明显Web mining is the collection of technologies to fulfill this potential.
网络挖掘是实现这种潜力的技术集合。
- Web Mining
- application of data mining and machine learning techniques to extract useful knowledge from the content, structure, and usage of Web resources.
应用数据挖掘和机器学习技术从网络资源的内容、结构和使用中提取有用的知识。
# Types of Web Mining
| Web Mining | ||
|---|---|---|
| Web Content Mining | Web Usage Mining | Web Structure Mining |
| Applications | ||
|
|
|
# Web Logs



# Usage Data Preprocessing
- Data Cleaning
- User/Session Identification
- Page View Identification
- Path Completion

| Example | |||||
|---|---|---|---|---|---|
| IP | Time | URL | Referrer | Agent | |
| 1 | www.aol.com | 08:30:00 | A | # | Mozilla/5.0; Win NT |
| 2 | www.aol.com | 08:30:01 | B | E | Mozilla/5.0; Win NT |
| 3 | www.aol.com | 08:30:01 | C | B | Mozilla/5.0; Win NT |
| 4 | www.aol.com | 08:30:02 | B | # | Mozilla/5.0; Win 95 |
| 5 | www.aol.com | 08:30:03 | C | B | Mozilla/5.0; Win 95 |
| 6 | www.aol.com | 08:30:04 | F | # | Mozilla/5.0; Win 95 |
| 7 | www.aol.com | 08:30:04 | B | A | Mozilla/5.0; Win NT |
| 8 | www.aol.com | 08:30:05 | G | B | Mozilla/5.0; Win NT |
# Two major challenges in PreProcessing 预处理过程中的两个主要挑战
- Identification of Users 用户识别
- Log data have mixed info of users and transactions
日志数据混杂了用户和交易的信息 - Some times, a user may not login the system
有时,用户可能无法登录
- Log data have mixed info of users and transactions
- Identification of Sessions 会话系统辨识
- A user may visit a same site for several times
用户可能多次访问同一个网站 - A user may leave the computer for a while
用户可能离开计算机一段时间 - User may have different intents in different sessions
用户可能在不同的会话中有不同的意图
- A user may visit a same site for several times
购物时,交易中有 item;网络中,会话记录了访问的 web page
# Mechanisms for User Identification 用户识别机制
| Method | Description | Privacy Concerm | Advantages | Disadvantages |
|---|---|---|---|---|
IP Address & Agent | Assume each unique IP address/Agent pair is a unigue user. | Low | Always available. No additional technology required. | Not guaranteed to be unique. Defeated by random or rotating IP. |
Embedded Session ID | Use dynamically generated pages to insent ID into every link. | Low / Medium | Always available. Independent of IP address. | No concept of a repeat visit. Requires fully dynamic site. |
Registration | Users explicitly sign-in to site. | Medium | Can track single individuals, not just browsers. | Not all users may be willing to register |
Cookie | Save an identifier on the client machine | Medium/ High | Can track repeat visits. | Can be disabled. Negative public image. |
Software Agent | Program loaded into browser that sends back usage data | High | Accurate usage data for a single Web site. | Likely to be refused. Negative public image. |
Modified Browser | Browser records usage data. | Very High | Accurate usage data across entire Web | Users must explicitly ask for software. |
# Sessionization Heuristics 会话启发法
# Time Oriented Heuristics 时间导向启发法
h1 :
- Total session duration may not exceed a threshold .
总的会话持续时间不能超过阈值 。 - Given , the timestamp for the first request in a constructed session , the request with timestamp is assigned to , iff
给定 ,构造会话 中的第一个请求的时间戳,如果,带有时间戳 的请求被分配给
- Total session duration may not exceed a threshold .
h2 :
- Total time spent on a page may not exceed a threshold .
在一个页面上花费的总时间不能超过阈值。 - Given , the timestamp for request assigned to constructed session , the next request with timestamp is assigned to , iff
给定分配给已构建会话 的请求的时间戳,如果,将具有时间戳 的下一个请求分配给
- Total time spent on a page may not exceed a threshold .
# Referrer Based Heuristic 基于来源启发法
- href :
- Given two consecutive requests and , with belonging to constructed session .
给定两个连续的请求 和,其中 属于构造的会话。 - Then is assigned to , if the referrer for was previously invoked in
然后 被分配给,如果 的来源先前在 中被调用
- Given two consecutive requests and , with belonging to constructed session .
Note: in practice, it is often useful to use a combination of time- and navigation-oriented heuristics in session identification.
注意:在实践中,在会话识别中结合使用面向时间和导航的试探法通常是有用的。
| Referrer Based Heuristic | |||||
|---|---|---|---|---|---|
| IP | Time | URL | Referrer | Agent | |
| 1 | www.aol.com | 08:30:00 | A | # | Mozilla/5.0; Win NT |
| 2 | www.aol.com | 08:30:01 | B | E | Mozilla/5.0; Win NT |
| 3 | www.aol.com | 08:30:01 | C | B | Mozilla/5.0; Win NT |
| 4 | www.aol.com | 08:30:02 | B | # | Mozilla/5.0; Win 95 |
| 5 | www.aol.com | 08:30:03 | C | B | Mozilla/5.0; Win 95 |
| 6 | www.aol.com | 08:30:04 | F | # | Mozilla/5.0; Win 95 |
| 7 | www.aol.com | 08:30:04 | B | A | Mozilla/5.0; Win NT |
| 8 | www.aol.com | 08:30:05 | G | B | Mozilla/5.0; Win NT |
- Identified Sessions:
:# → A → B → G from references 1, 7, 8
:E → B → C from references 2, 3
:# → B → C from references 4, 5
:# → F from reference 6
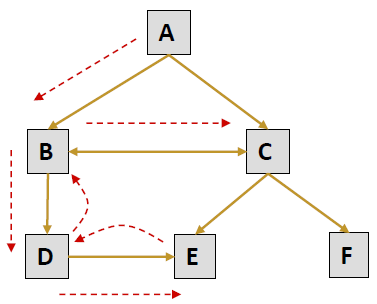
Path Completion 路径完成
- User's actual navigation path: A → B → D → E → D → B → C
- What the server log shows: 服务器日志显示
URL Referrer A -- B A D B E D C B - Need knowledge of link structure to complete the navigation path.
需要了解链接结构才能完成导航路径。 - There may be multiple candidate for completing the path. For example consider the two paths : E → D → B → C and E → D → B → A → C.
可能有多个候选项用于完成路径。例如,考虑这两条路径:E → D → B → C 和 E → D → B → A → C - In this case, the referrer field allows us to partially disambiguate.
在这种情况下,referer 字段允许我们部分消除歧义。
But, what about: E → D → B → A → B → C? - One heuristic: always take the path that requires the fewest number of “back” references.
一个启发:总是选择需要最少 “返回” 引用的路径。 - Problem gets much more complicated in frame-based sites.
在基于框架的站点中,问题变得更加复杂。
# Sessionization Example
| Time | IP | URL | Ref | Agent |
|---|---|---|---|---|
| 0:01 | 1.2.3.4 | A | - | IE5;Win2k |
| 0:09 | 1.2.3.4 | B | A | IE5;Win2k |
| 0:10 | 2.3.4.5 | C | - | IE4;Win98 |
| 0:12 | 2.3.4.5 | B | C | IE4;Win98 |
| 0:15 | 2.3.4.5 | E | C | IE4;Win98 |
| 0:19 | 1.2.3.4 | C | A | IE5;Win2k |
| 0:22 | 2.3.4.5 | D | B | IE4;Win98 |
| 0:22 | 1.2.3.4 | A | - | IE4;Win98 |
| 0:25 | 1.2.3.4 | E | C | IE5;Win2k |
| 0:25 | 1.2.3.4 | C | A | IE4;Win98 |
| 0:33 | 1.2.3.4 | B | C | IE4;Win98 |
| 0:58 | 1.2.3.4 | D | B | IE4;Win98 |
| 1:10 | 1.2.3.4 | E | D | IE4;Win98 |
| 1:15 | 1.2.3.4 | A | - | IE5;Win2k |
| 1:16 | 1.2.3.4 | C | A | IE5;Win2k |
| 1:17 | 1.2.3.4 | F | C | IE4;Win98 |
| 1:25 | 1.2.3.4 | F | C | IE5;Win2k |
| 1:30 | 1.2.3.4 | B | A | IE5;Win2k |
| 1:36 | 1.2.3.4 | D | B | IE5;Win2k |
首先要识别用户
- Sort users (based on IP+Agent) 对用户进行排序(基于 IP + 代理)
| 0:01 | 1.2.3.4 | A | - | IE5;Win2k |
| 0:09 | 1.2.3.4 | B | A | IE5;Win2k |
| 0:19 | 1.2.3.4 | C | A | IE5;Win2k |
| 0:25 | 1.2.3.4 | E | C | IE5;Win2k |
| 1:15 | 1.2.3.4 | A | - | IE5;Win2k |
| 1:26 | 1.2.3.4 | F | C | IE5;Win2k |
| 1:30 | 1.2.3.4 | B | A | E5;Win2k |
| 1:36 | 1.2.3.4 | D | B | IE5;Win2k |
| 0:10 | 2.3.4.5 | C | - | IE4;Win98 |
| 0:12 | 2.3.4.5 | B | C | IE4;Win98 |
| 0:15 | 2.3.4.5 | E | C | IE4;Win98 |
| 0:22 | 2.3.4.5 | D | B | IE4;Win98 |
| 0:22 | 1.2.3.4 | A | - | IE4;Win98 |
| 0:25 | 1.2.3.4 | C | A | IE4;Win98 |
| 0:33 | 1.2.3.4 | B | C | IE4;Win98 |
| 0:58 | 1.2.3.4 | D | B | IE4;Win98 |
| 1:10 | 1.2.3.4 | E | D | IE4;Win98 |
| 1:17 | 1.2.3.4 | F | C | IE4;Win98 |
- Sessionize using heuristics 使用启发式进行会话
| 0:01 | 1.2.3.4 | A | - | IE5;Win2k |
| 0:09 | 1.2.3.4 | B | A | IE5;Win2k |
| 0:19 | 1.2.3.4 | C | A | IE5;Win2k |
| 0:25 | 1.2.3.4 | E | C | IE5;Win2k |
| 1:15 | 1.2.3.4 | A | - | IE5;Win2k |
| 1:26 | 1.2.3.4 | F | C | IE5;Win2k |
| 1:30 | 1.2.3.4 | B | A | E5;Win2k |
| 1:36 | 1.2.3.4 | D | B | IE5;Win2k |
| 0:01 | 1.2.3.4 | A | - | IE5;Win2k |
| 0:09 | 1.2.3.4 | B | A | IE5;Win2k |
| 0:19 | 1.2.3.4 | C | A | IE5;Win2k |
| 0:25 | 1.2.3.4 | E | C | IE5;Win2k |
| 1:15 | 1.2.3.4 | A | - | IE5;Win2k |
| 1:26 | 1.2.3.4 | F | C | IE5;Win2k |
| 1:30 | 1.2.3.4 | B | A | E5;Win2k |
| 1:36 | 1.2.3.4 | D | B | IE5;Win2k |
The h1 heuristic (with timeout variable of 30 minutes) will result in the two sessions given above.
h1 启发式 (超时变量为 30 分钟) 将导致上述两个会话。
How about the heuristic href?
启发式的 href 怎么样?
How about heuristic h2 with a timeout variable of 10 minutes?
超时变量为 10 分钟的启发式 h2 怎么样?
- Sessionize using heuristics (another example)
| 0:22 | 1.2.3.4 | A | - | IE4;Win98 |
| 0:25 | 1.2.3.4 | C | A | IE4;Win98 |
| 0:33 | 1.2.3.4 | B | C | IE4;Win98 |
| 0:58 | 1.2.3.4 | D | B | IE4;Win98 |
| 1:10 | 1.2.3.4 | E | D | IE4;Win98 |
| 1:17 | 1.2.3.4 | F | C | IE4;Win98 |
In this case, the referrer-based heuristics will result in a single session, while the h1 heuristic (with timeout = 30 minutes) will result in two different sessions.
在这种情况下,基于引用的启发式将导致单个会话,而 h1 启发式 (超时 = 30 分钟) 将导致两个不同的会话。
How about heuristic h2 with timeout = 10 minutes?
超时 = 10 分钟的启发式 h2 怎么样?
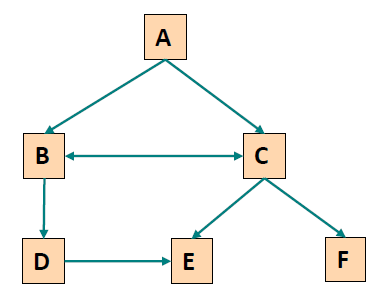
- Perform Path Completion 执行路径补全
A→C,C→B,B→D,D→E,C→F
Need to look for the shortest backwards path from E to C based on the site topology.
需要根据站点拓扑查找从 E 到 C 的最短反向路径。
Note, however, that the elements of the path need to have occurred in the user trail previously.
但是,请注意,路径的元素需要以前在用户跟踪中出现。E→D,D→B,B→C需要加到D→E,C→F之间
# Web Mining by Association Rules
# Market Analysis vs Web Mining
- Market Analysis 市场分析
- We explore associations among items in transactional databases
我们探索事务数据库中项目之间的关联 - Items may show up together in different transactions, such as each receipt
项目可能会一起出现在不同的交易中,例如每张收据
- We explore associations among items in transactional databases
- Web Mining 网络挖掘
- We can explore the associations among Web pages or behaviors in Web logs
我们可以探索 Web 日志中网页或行为之间的关联 - Web pages or behaviors may show up together in different sessions
网页或行为可能会一起出现在不同的会话中
- We can explore the associations among Web pages or behaviors in Web logs
# Web Usage Mining by Association Rules 基于关联规则的 Web 使用挖掘
- Web Association Rule Mining Web 关联规则挖掘
- The process is similar to association rule mining, but you need to apply the rule mining per sessions
该过程类似于关联规则挖掘,但您需要在每个会话中应用规则挖掘 - Examples
- 60% of clients who accessed
/products/, also accessed/products/software/webminer.htm
60% 访问了... 也访问了... 的客户 - 30% of clients who accessed
/special-offer.html, placed an online order in/products/software
30% 的客户访问... 在... 中在线下单
- 60% of clients who accessed
- The process is similar to association rule mining, but you need to apply the rule mining per sessions
- Web Sequential Mining Web 序列挖掘
- In association rule mining, the sequence does not matter.
在关联规则挖掘中,顺序无关紧要。
But on the Web, the sequence takes a key role.
但在网络上,序列扮演着关键角色。
For example,{A → B → C} → {D}may be very different from{B → A →C} → {D} - The process is similar to the association rule mining, but you need to consider sequences when you calculate support and confidence values·
该过程类似于关联规则挖掘,但在计算支持和置信值时,需要考虑序列。
顺序不一致,不能算到一起
- In association rule mining, the sequence does not matter.
# Web Log Data
If you’d like to work on Web mining…
- NASA Web Logs, http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html
- Wikipedia Web Logs, http://opensource.indeedeng.io/imhotep/docs/sample-data/
- MSNBC.com Web Data, http://archive.ics.uci.edu/ml/datasets/MSNBC.com+Anonymous+Web+Data
- Microsoft Web Data, http://archive.ics.uci.edu/ml/datasets/Anonymous+Microsoft+Web+Data
- DePaul CTI Web Logs, http://facweb.cs.depaul.edu/mobasher/classes/ect584/lectures/cti-april2003-clean-log.zip